1 引言
Internet上信息資源的飛速增長,使得人們越來越習慣于在網絡上搜集自己所需的信息。其中各類文獻資源信息也以電子文檔的形式,在網絡上廣為傳播。然而要從龐大的文獻資料庫中準確、方便、迅速地找到并獲得自己所需的信息,卻往往比較困難。傳統的基于關鍵詞匹配的文獻信息檢索方式存在一些弊端,如“忠實表達”、“表達差異”[1]等問題。這種方式對文獻資源的處理粒度大,網絡搜索引擎在執行用戶查詢的時候,只是提取用戶查詢請求中的關鍵詞,會丟失用戶查詢的語義信息和相關同義、近義以及上下位關系外延的資料信息,這些直接導致檢索結果的不準確。以關鍵詞檢索文獻資源的方式無法提供高質量的知識服務。
解決上述問題的關鍵在于把資源檢索從傳統的關鍵詞層面提高到語義知識層面。Tim Berners-Lee于2000年提出了語義Web[2]的概念。語義Web是一種能理解人類語言的智能網絡,它的實現能有效提高互聯網使用效率。要實現檢索系統的語義化,很自然的需要引入本體(Ontology)[3]。Ontology作為語義Web的核心概念和技術,本身具有一定的推理能力和概念知識結構,能很好的描述實例的內涵及實例與實例之間的關系,經過推理還能表示隱含的各種知識之間的關系。通過本體,搜索程序可以進行基于語義的精確搜索,可以把頁面上的文獻資源與某些知識結構和規則鏈接起來。基于Ontology 的文獻領域語義檢索機制可以從語義層上支持對文獻資源的查詢和共享,從而在一定程度上提高了文獻檢索的查準率和查全率。
2 文獻本體的構建
2.1 本體知識
在語義Web中,Ontology具有非常重要的地位,彌補了資源描述的不足,是解決語義層次上Web資源共享和交換的基礎。Studer等人認為"An ontology is a formal specification of a shared conceptualization"[4],這個是目前為止最完善的本體的定義。文獻[5]分析了本體的概念、本體描述語言、本體的分類、本體的構建原則。文獻[6]給出本體包含的4層含義、本體的目標、領域本體及其構建。總結這些文獻資源可以發現:本體不僅提供了對領域知識的捕獲、描述和共同理解,還給出不同層次模型中概念間相互關系的明確定義,具有較強的表達能力。本體的核心就是知識共享,通過減少概念和術語上的歧義,使得人們和組織(或者機器)之間的交流準確無歧義。
2.2 本體構建方法
一個本體由多個概念以及關系組成,本體的創建就是用來表達概念和概念之間的各種關系。根據具體工程和領域的不同,形成不同的構建方法。文獻[7]詳細介紹了本體的構建方法,如七步法、生命周期法、骨架法、IDEF-5方法等。文獻[8]以七步法的思路為基礎,綜合生命周期法和軟件工程的原型法,以骨架法為本體構建的指導方針,提出了一個創新的構建領域本體的原型七步法,過程是螺旋式上升的,符合人們的思維認知規律,操作性和擴展性強。
2.3 文獻本體的構建
文獻領域知識庫的建立是實現語義檢索和推理的關鍵步驟。本文以七步法的方法為基礎,根據文獻資源本體構建的需要,提出一種較為簡單的本體構建方法,圖1描述了該構建方法的流程。

圖1 本體構建流程圖
文獻領域本體描述了文獻中的實體、實體之間的各種關聯以及實體的屬性和關聯的屬性。基于本體的文獻語義檢索系統中關注文獻(Paper)、作者(Author)和期刊(Magazine)三類重要的概念實體。三個概念又通過相應的屬性關聯起來,定義了三個對象屬性(ObjectProperty),其中isPublished描述了文獻與期刊之間的出版關系,其定義域是Paper類,值域是Magazine類;Citing(isCited)等屬性的定義域和值域都是Paper類,它描述了論文與論文之間相互引用的關系;對象屬性hasAuthor定義域為Author類,值域為Paper類,它描述了作者與文獻之間的關系。建立的文獻領域本體如圖2所示。用戶通過檢索文獻可以了解到文獻的作者、內容、類型、關鍵詞、發表時間、引用和被引用的文獻等。而同引和同被引可以通過文獻的引用和被引用情況推理出來。
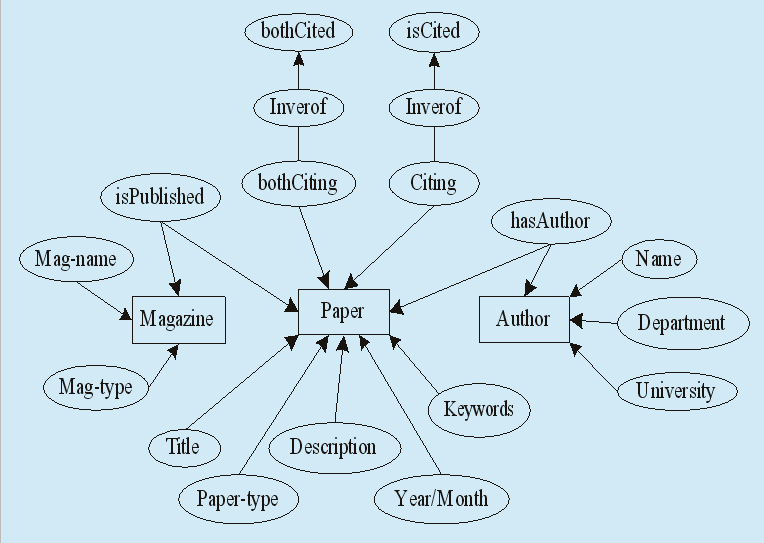
圖2 文獻領域本體
3 文獻領域語義檢索的實現
3.1 基于本體的文獻領域語義檢索模型
分析了傳統的文獻檢索模型之后,提出了基于Ontology的文獻領域語義檢索系統模型,如圖3所示。該模型采用基于B/S 的三層結構,即把該系統分為三層:表示層、業務邏輯層和數據層。用戶向系統發出檢索請求,系統對檢索請求進行信息提取,根據檢索信息和所定義的語義規則對文獻領域本體進行語義推理,從而實現用戶的檢索要求。
3.2 實驗環境及工具
本系統所使用的開發工具為Java、Jena2.5、protégé3.4本體開發工具;使用OWL本體描述語言和SWRL規則語言[9];Tomcat6.0作為Web服務器;實驗環境為:CPU InterCore 2、1.83GHz、1G內存、80G硬盤的Windows XP操作系統進行實驗。
3.3 系統語義推理
基于Ontology的文獻領域語義檢索系統,是關于語義層面的檢索,關鍵在于概念及其概念之間關系的推理,這種推理可以將隱含在顯式定義和聲明中的知識通過一種處理機制提取出來,即根據用戶提交的語義查詢進行相應的語義擴展,譬如可以從檢索出的文獻引用關系中推理出它的同引和同被引文獻。然而這種推理需要相應的規則,沒有規則系統是無法理解本體概念之間的語義,只能進行關鍵字機械的匹配。Jena是基于規則的推理機,因此在基于本體的文獻檢索系統中建立了能真實表現概念之間關系的規則,實現系統的語義理解,從而檢索出滿足用戶需求的信息。
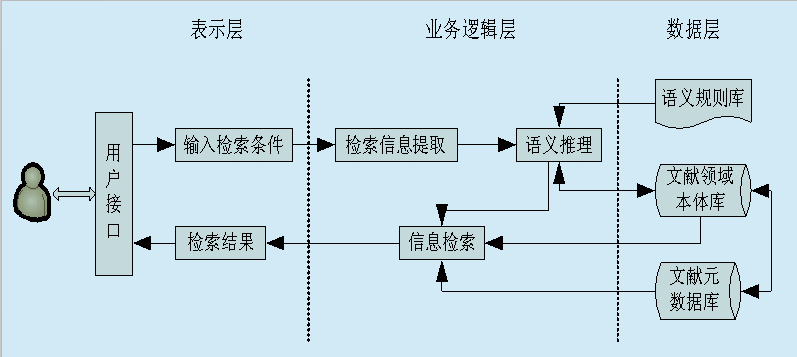
圖3 基于Ontology的文獻領域
語義檢索系統模型
(用戶自定義規則的補充表達),使得在protégé下編輯規則,更加靈活和直觀。首先自定義了一組語法:符號“→”表示蘊涵,將前提和結論邏輯關聯起來;變量以“?”開頭;引用的子公式插入符號“∧”進行連接;同時提供內置函數,類似方法調用,返回值為變量的值。

以一階謂詞邏輯的角度來分析上述規則,可以得到如下的語義:如果變量x是類A的實例,同時也是類B的實例,那么變量x也是類C的實例。其部分推理規則如下所示:
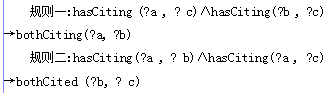
規則一說明:文獻a引用了文獻c,文獻b也引用了文獻c, a和b的關系為不相等,則可以推出a和b的關系為同引(bothCiting)關系;規則二說明:文獻a引用了文獻b,文獻a又引用了文獻c ,b和c的關系不相等,則可以推出b和c之間是同被引(bothCited)的關系。
4 實驗結果與分析
通常用查準率(Precision)和查全率(Recall)來衡量智能信息檢索系統的性能。查準率主要描述的是檢索結果的有用性,是檢索結果中有效信息量與檢索總量之間的比例關系。查全率主要描述檢索結果的遺漏情況,表示的是信息檢索結果中有用信息量與用戶需求信息量之間的比例。設檢索出的文檔數目為N, 檢索出的相關文檔數目為Ra, 所有相關文檔數目為Rb,則查準率和查全率的計算方法如下:
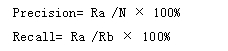
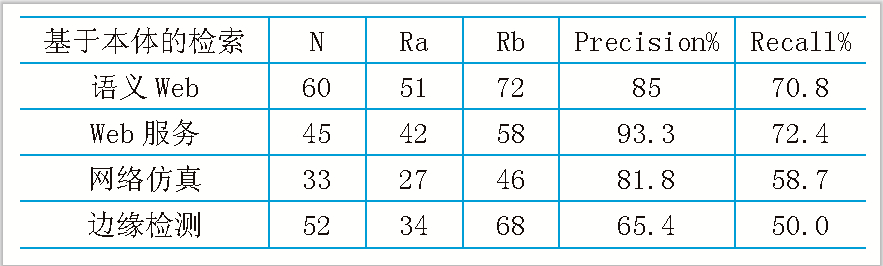
表1 基于本體的文獻語義檢索結果
本文選取互聯網上計算機領域的相關科技文獻作為實驗對象,以2008-2011年期間的在計算機相關期刊上發表的學術論文,針對計算機不同的領域,選取300篇文獻作為本體庫。對采用Ontology技術前后的檢索性能進行比較, 得到的結果如表1、2所示。
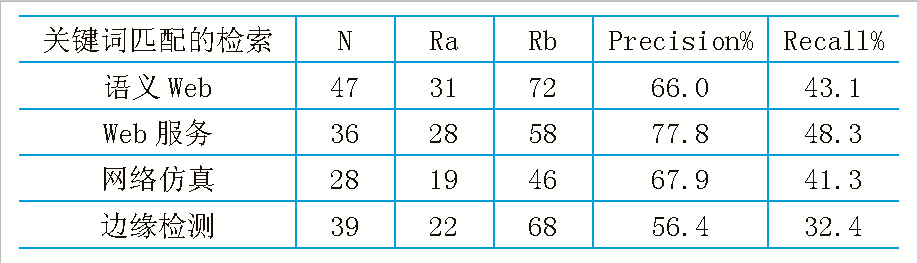
表2 基于傳統關鍵詞匹配的檢索結果
實驗結果表明:基于Ontology的文獻檢索系統返回符合檢索條件的大量的、精確的文獻資源,包括文獻編號﹑標題﹑作者﹑關鍵詞﹑文獻出處﹑內容﹑同引和被同引等詳細內容信息。本系統的查全率與查準率高于傳統的關鍵詞檢索的效率,這主要是因為系統在本體的基礎上對檢索關鍵字進行了語義的分析、擴展和推理。因此將本體技術應用到文獻檢索領域是可行的。
5 結束語
結合文獻信息的特點,本文提出了一個新的本體構建方法,創建了文獻領域本體,建立了推理規則,構建了一個文獻領域語義檢索系統模型。該模型可以方便、快捷的查找出目標文獻。用戶向系統輸入檢索請求可以通過對本體的推理,檢索出目標文獻引用的文獻、引用目標文獻的文獻、同引關系和被同引關系的文獻。最后通過實驗,驗證了基于本體的文獻領域檢索系統的優越性。
參考文獻:
[1] 朱慶生,鄒景華.基于本體論的論文檢索[J].計算機科學,2005.32(5):172-173,176.
[2] T BERNERS-LEE,J HENDLER,O Lassila[J].The Semantic Web.NewYork:Scientific American,2001:284(5):34-43.
[3] What is an ontology?[CP/OL].[2011-02-10].
http://www-ksl.stanford.edu/kst/what-is-an-ontology.html
[4] FENSEL D.ONTOLOGIES.Silver Bullet for Knowledge Management and ElectronicCommerce[M]. Stanford:Springer,2001:50-53.
[5] 劉垣,君忠.本體理論及其在E-Learning中的應用[J].計算機應用與軟件,2012,29(4):114-117.
[6] 柴留祥,何豐.基于Jena及其本體推理的研究[J].計算機技術與發展,2011,21(11):117-119,123.
[7] USEHOLD M.Ontologies principles,methods and applications[J].Knowledge Engineering Review,1996,6(11):2-3.
[8] 梁婷婷,李春青.一種領域本體構建方法及其在相片管理中的應用[J].計算機系統應用, 2012.12(5):140-144,104.
[9] 陳布偉,李冠宇,張俊,李佳燕.基于語義網規則語言的推理機制框架設計[J].計算機工程與設計,2010,31(4):847-849,853.